
캐글 코드
lstm을 통한 개채명 인식
백준파이썬개발자:프로젝트골드
2024. 4. 22. 18:16
반응형
#)1라이브러리 임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import urllib.request
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import to_categorical
#)2 데이터 받기
data = pd.read_csv("/content/drive/MyDrive/kdt/refer to/kaggle_code/ner_dataset.csv", encoding="latin1")
#)3 데이터 보기

#)4결측치 보기
print('어떤 열에 Null값이 있는지 출력')
print('==============================')
data.isnull().sum()
#)5 Tag의 개수 카운트하기
print('Tag 열의 각각의 값의 개수 카운트')
print('================================')
print(data.groupby('Tag').size().reset_index(name='count'))#)6누락된 값이 있다면 이전값으로 대체하기
data = data.fillna(method="ffill")
print(data.tail())#)7 word와 label을 따로 저장하기
sentences, ner_tags = [], []
for tagged_sentence in tagged_sentences: # 47,959개의 문장 샘플을 1개씩 불러온다.
# 각 샘플에서 단어들은 sentence에 개체명 태깅 정보들은 tag_info에 저장.
sentence, tag_info = zip(*tagged_sentence)
sentences.append(list(sentence)) # 각 샘플에서 단어 정보만 저장한다.
ner_tags.append(list(tag_info)) # 각 샘플에서 개체명 태깅 정보만 저장한다.#)8word의 길이 시각화 하기
print('샘플의 최대 길이 : %d' % max(len(l) for l in sentences))
print('샘플의 평균 길이 : %f' % (sum(map(len, sentences))/len(sentences)))
plt.hist([len(s) for s in sentences], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()#)9 가장많이 사용된단어 OOV처리해주기
# 모든 단어를 사용하며 인덱스 1에는 단어 'OOV'를 할당.
src_tokenizer = Tokenizer(oov_token='OOV')
# 태깅 정보들은 내부적으로 대문자를 유지한 채 저장
tar_tokenizer = Tokenizer(lower=False)
src_tokenizer.fit_on_texts(sentences)
tar_tokenizer.fit_on_texts(ner_tags)
#)10 데이터를 숫자형식으로 바꾸어 주기
X_data = src_tokenizer.texts_to_sequences(sentences)
y_data = tar_tokenizer.texts_to_sequences(ner_tags)#)11 인덱스가 0이면 PAD라는 값으로 만들기
word_to_index = src_tokenizer.word_index
index_to_word = src_tokenizer.index_word
ner_to_index = tar_tokenizer.word_index
index_to_ner = tar_tokenizer.index_word
index_to_ner[0] = 'PAD'
print(index_to_ner)#)12 수치형 데이터에 패딩을 해줌
max_len = 70
X_data = pad_sequences(X_data, padding='post', maxlen=max_len)
y_data = pad_sequences(y_data, padding='post', maxlen=max_len)
#)13 LSTM을 통해서 학습 하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, InputLayer, Bidirectional, TimeDistributed, Embedding
from tensorflow.keras.optimizers import Adam
embedding_dim = 128
hidden_units = 256
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim, mask_zero=True))
model.add(Bidirectional(LSTM(hidden_units, return_sequences=True)))
model.add(TimeDistributed(Dense(tag_size, activation=('softmax'))))
model.compile(loss='categorical_crossentropy', optimizer=Adam(0.001), metrics=['accuracy'])
history = model.fit(X_train, y_train, batch_size=128, epochs=6, validation_split=0.1)
#)14 LSTM을 통한 예측하기
i = 13 # 확인하고 싶은 테스트용 샘플의 인덱스.
y_predicted = model.predict(np.array([X_test[i]])) # 입력한 테스트용 샘플에 대해서 예측 y를 리턴
y_predicted = np.argmax(y_predicted, axis=-1) # 확률 벡터를 정수 인코딩으로 변경함.
labels = np.argmax(y_test[i], -1) # 원-핫 인코딩을 다시 정수 인코딩으로 변경함.
print("{:15}|{:5}|{}".format("단어", "실제값", "예측값"))
print(35 * "-")
for word, tag, pred in zip(X_test[i], labels, y_predicted[0]):
if word != 0: # PAD값은 제외함.
print("{:17}: {:7} {}".format(index_to_word[word], index_to_ner[tag], index_to_ner[pred]))#)15 LSTM을 통한 예측하기_2
hit = 0 # 정답 개수
for tag, pred in zip(labels, predicted):
if tag == pred:
hit +=1 # 정답인 경우에만 +1
accuracy = hit/len(labels) # 정답 개수를 총 개수로 나눈다.
print("정확도: {:.1%}".format(accuracy))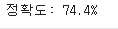
반응형